If you’re wondering if it’s really that bad, have this quote:
GNOME sysadmin, Bart Piotrowski, kindly shared some numbers to let people fully understand the scope of the problem. According to him, in around two hours and a half they received 81k total requests, and out of those only 3% passed Anubi’s proof of work, hinting at 97% of the traffic being bots
And this is just one quote. The article is full of quotes of people all over reporting they can’t focus on their work because either the infra they rely on is constantly down, or because they’re the ones fighting to keep it functional.
This shit is unsustainable. Fuck all of these AI companies.
Cache size is limited and can usually only hold a limited number of most recently viewed pages. But these bots go through every single page on the website, even old ones that are never viewed by users. As they only send one request per page, caching doesnt really help.
The bots scrape costly endpoints like the entire edit histories of every page on a wiki. You can’t always just cache every possible generated page at the same time.

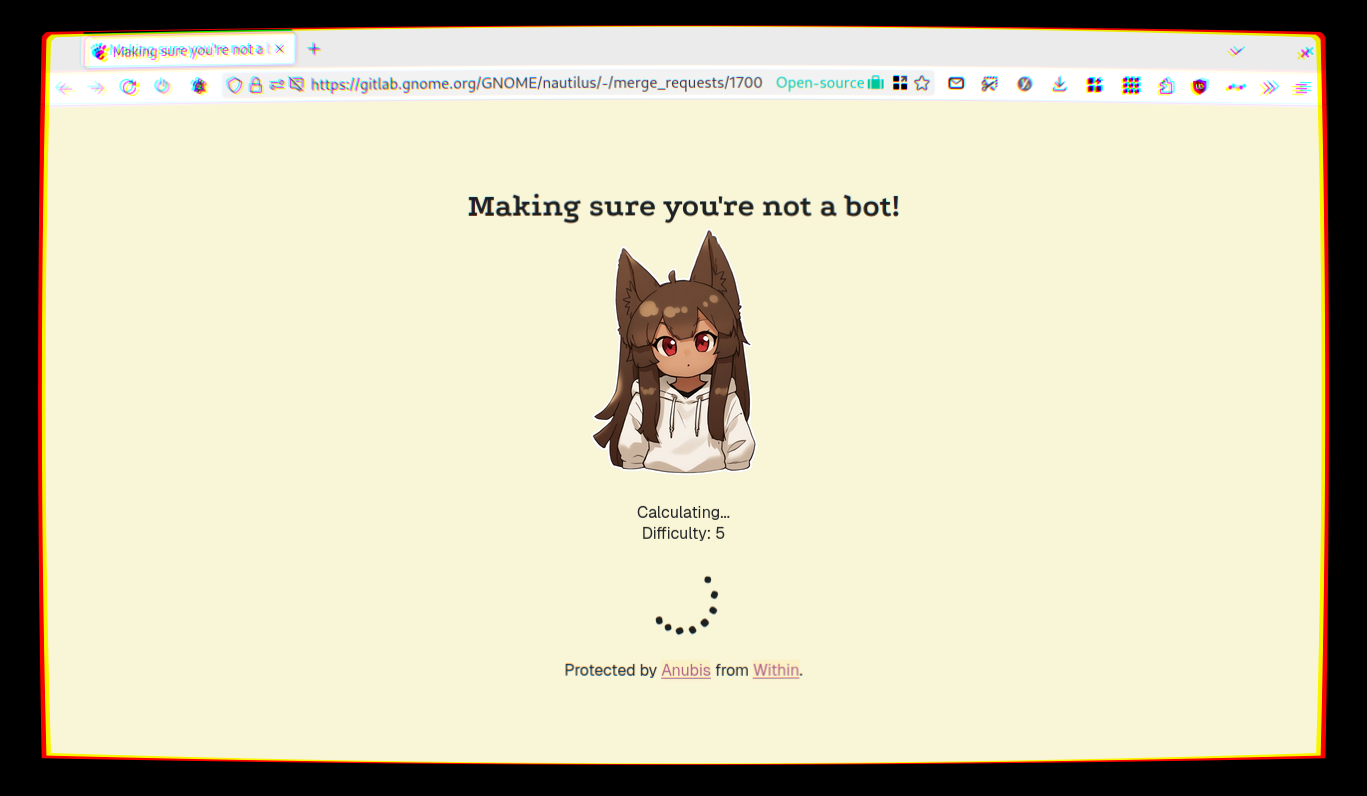
If you’re wondering if it’s really that bad, have this quote:
And this is just one quote. The article is full of quotes of people all over reporting they can’t focus on their work because either the infra they rely on is constantly down, or because they’re the ones fighting to keep it functional.
This shit is unsustainable. Fuck all of these AI companies.
Its absolutely sustainable. Just cache it. Done.
I’m sure that if it was that simple people would be doing it already…
Cache size is limited and can usually only hold a limited number of most recently viewed pages. But these bots go through every single page on the website, even old ones that are never viewed by users. As they only send one request per page, caching doesnt really help.
Cache size is definitely not an issue, especially for these companies using cloudflare
It is an issue for the open source projects discussed in the article.
The bots scrape costly endpoints like the entire edit histories of every page on a wiki. You can’t always just cache every possible generated page at the same time.
Of course you can. This is why people use CDNs.
Put the entire site on a CDN with a cache of 24 hours for unauthenticated users.